
前言
本系列主要是对pytorch基础知识学习的一个记录,尽量保持博客的更新进度和自己的学习进度。本人也处于学习阶段,博客中涉及到的知识可能存在某些问题,希望大家批评指正。另外,本博客中的有些内容基于吴恩达老师深度学习课程,我会尽量说明一下,但不敢保证全面。
一、构造数据类Dataset
要想使用Dataloader,我们需要构造一个适用于待解决问题的一个数据类,该数据类必须继承Dataset,下面是一个简单的例子:
from torch.utils.data import DataLoader, Dataset
class MnistData(Dataset):
def __init__(self, data_path, label_path):
super(MnistData, self).__init__()
self.data, self.label = load_mnist(data_path, label_path)
self.data = self.data[0:1000, :]
self.label = self.label[0:1000]
self.len = self.label.shape[0]
def __getitem__(self, index):
return self.data[index], self.label[index]
def __len__(self):
return self.len 这里我为手写数字图片构造了一个数据类,因为数据集比较简单(数据+标签),因此数据类中的成员变量也不是很多。我个人觉得还是要具体问题具体分析,当需要处理文本数据时,构造的类就会复杂许多。==loadmnist== 是读取文件的一个函数。
当你构建数据类时,你必须继承 ==Dataset== 类,并复写 getitem 函数和 len _ 函数
二、使用Dataloader
pytorch给出的Dataloader解释如下:
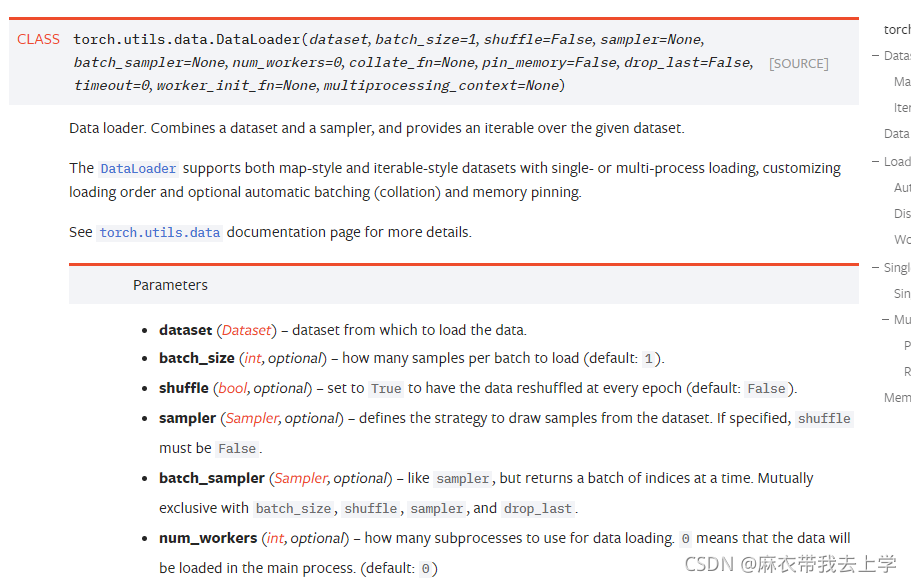
Dataloder中参数还是非常多的,我暂时用到过的并不多,主要是以下三个参数:
1.dataset:Dataset类型,传入提前构造好的数据类。
2.batch_size:int类型,批处理的大小,不用自己划分数据集。
3.shuffle:bool类型,当设置为True时,每个epoch会随机打乱数据集。使用Dataloader:
mnist_data = MnistData(train_data_path, train_label_path)
train_loader = DataLoader(dataset=mnist_data, batch_size=32, shuffle=True)遍历Dataloader:
for epoch in range(epoch_num):
epoch_cost = 0
for i, data in enumerate(train_loader):
img_data, labels = data总结
本人对Dataloader的了解其实并不很透彻,只会一些基本使用,在今后的情形中若碰见比较复杂的情形,我会完善这一篇博客。