
前言
本系列主要是对pytorch基础知识学习的一个记录,尽量保持博客的更新进度和自己的学习进度。本人也处于学习阶段,博客中涉及到的知识可能存在某些问题,希望大家批评指正。另外,本博客中的有些内容基于吴恩达老师深度学习课程,我会尽量说明一下,但不敢保证全面。
一、问题描述
此次需要构建的神经网络其实和前几次相同,为了能更直观的理解问题,绘制了一张精美的神经网络结构图:
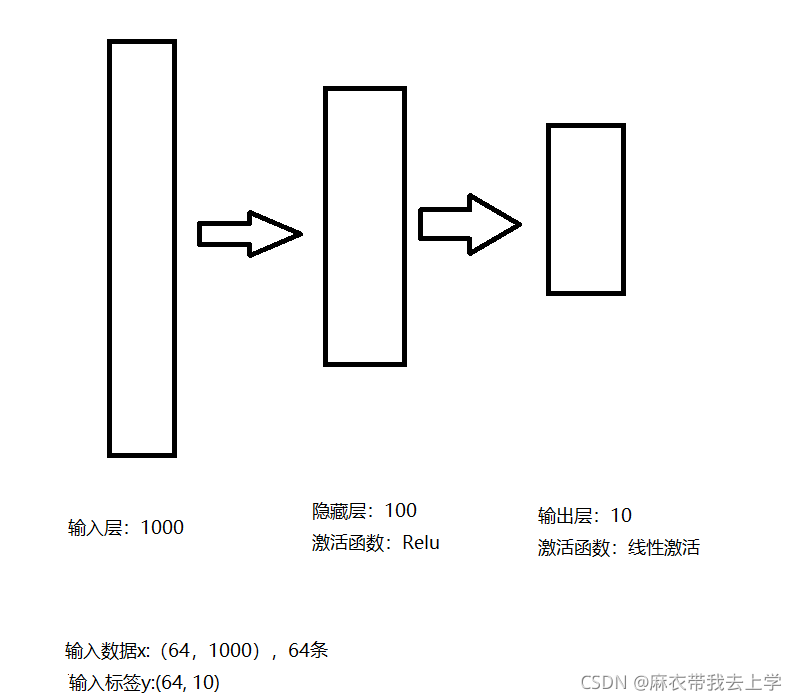
到目前为止,我们已经使用了numpy,tensor,Pytorch自动求导以及Pytorch的nn模块来实现同一个神经网络。
我们在nn的基础上使用优化算法来对神经网络进行优化,看过吴恩达老师深度学习课程的应该对优化算法有大致了解,一般来说有三种:动量梯度下降法(Momentum)、RMSprop算法和Adam优化算法。
每个优化算法有对应的数学公式,在这里就不细说了。需要明白的是,这些优化算法主要改变反向传播后的参数更新环节,目的是在于加快神经网络的训练过程。
二、官方文档代码
Pytorch已经将优化算法封装成optim包,我们要做的是把需要优化的参数以及使用到的学习率传入函数中即可。
import torch
N, D_in, H, D_out = 64, 1000, 100, 10
x = torch.randn(N, D_in)
y = torch.randn(N, D_out)
# 定义神经网络需要计算的层
model = torch.nn.Sequential(torch.nn.Linear(D_in, H),
torch.nn.ReLU(),
torch.nn.Linear(H, D_out))
# 定义神经网络的损失函数
loss_fn = torch.nn.MSELoss(reduction="sum")
learning_rate = 1e-4
# 定义使用的优化算法,这里使用的的是Adam优化算法
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
for t in range(500):
# 前向传播
y_pred = model(x)
# 计算损失
loss = loss_fn(y_pred, y)
print(t, loss.item())
# 梯度清零
optimizer.zero_grad()
# 反向传播
loss.backward()
# 参数更新
optimizer.step()上述代码与之前代码的差别在于使用到了优化器,并且参数的更新去梯度的清零都是在优化器的基础上完成的。接下来我会浅析一下optimizer的工作原理,为什么是"浅析",是因为我不太懂其更底层的代码。
三、optimizer的工作原理
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate) 我们通过上述代码初始化了一个优化器,该优化器使用的是Adam优化算法,optim包里面还包含了其他优化算法。初始化时我们将我们定义的神经网络中的参数传入优化器中,并传入我们定义的学习率。
然后在反向传播完成后,调用optim包中的step()方法完成参数更新:
# 参数更新
optimizer.step() 这里我产生了一个疑问:为什么调用optim包中的函数,会对model对象中的属性进行更新。
在前面我们知道,model.parameters()会返回一个迭代器,对这个迭代器遍历可以依次得到神经网络中的参数,也就是w1,b1,w2,b2。我们打印这四个值的id号:
pa = model.parameters()
for param in pa:
print(id(param))结果如下:
2268871549080
2268871549160
2268871549240
2268871549320 我们查看 ==torch.optim.Adam()== 返回值 ==optimizer== 的属性:
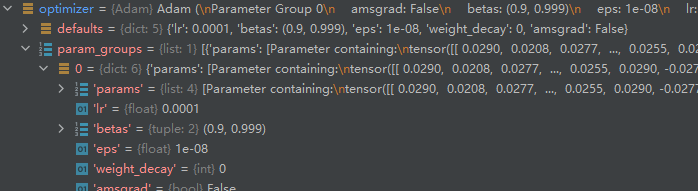
optimizer有列表类型的属性 ==param_groups== ,其长度为1。查看列表中的元素,发现是一个字典类型的数据,该字典类型数据底下有key值为"params"的项,其value的值为一个列表,让我们打印列表中元素的id值:
for param2 in optimizer.param_groups[0]["params"]:
print(id(param2))结果如下:
2017646698648
2017646698728
2017646698808
2017646698888 可以看出,打印结果与上面打印的model.parameters()中参数id值完全相同,这就解释了为什么调用optim中的方法会对model中的属性产生改变。至于为什么会这样,个人推测是采用了深复制,所以requires_grad属性的值也为True,感兴趣的可以去看看源码。
关于使用 ==step()== 更新参数的原理,我暂时还未弄明白,但是查阅相关资料后了解到,optim的所有优化函数均有step()方法。
总结
使用Pytorch的优化器 ==optim== 的大致步骤为:定义一个需要的优化器,并传入需要优化的参数和优化使用到的学习率;在反向传播前利用优化器对参数梯度进行清零;反向传播结束后利用优化器对参数进行更新。可以看出,使用优化器后,对神经网络参数的操作可以直接在优化器上进行。
view