
前言
本系列主要是对pytorch基础知识学习的一个记录,尽量保持博客的更新进度和自己的学习进度。本人也处于学习阶段,博客中涉及到的知识可能存在某些问题,希望大家批评指正。另外,本博客中的有些内容基于吴恩达老师深度学习课程,我会尽量说明一下,但不敢保证全面。
提示:以下是本篇文章正文内容,下面案例可供参考
一、吴恩达深度学习视频
相信很多人深度学习的入门教程是吴恩达老师的深度学习视频,吴恩达老师有关线性激活的运算推导相信大家都不陌生。在使用numpy复现一个简单的神经网络时,用一个简单的例子解释参数维度的变化:
1.输入样本(20,50),即单个样本是20维的向量,每次输入50个,每一列为一个样本
2.输入层:第一层=20:70,即第一层隐藏层有70个神经元
3.W=(n[L],n[L-1])=70:20,偏移向量b=(70,)
4.线性激活:A[1]=WX+b,A[1]的维度为(70,50)也就是说,每层weight的初始化维度为(输入层除外):(n[L], n[L-1])。而输入样本的维度为(单个样本维度,样本个数),即输入的每一列为单个样本,每一层计算的A[L]的每一列对应的是单个样本的计算值。
二、torch.nn.Linear
根据pytorch官方文档给出的解释如下:
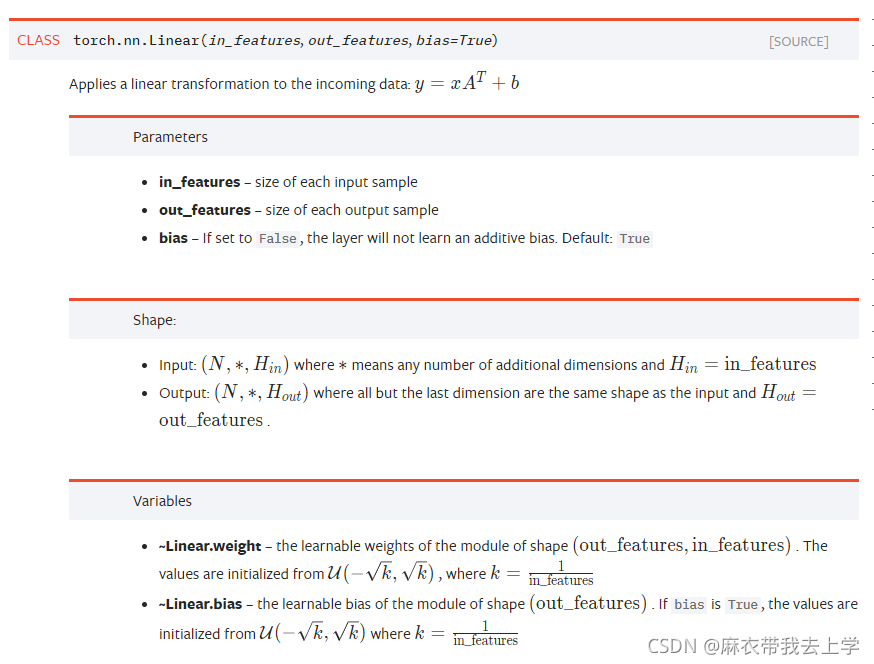
从官方文档给出的解释来看,torch.nn.Linear的两个输入为(输入的维度,输出的维度),也就是(n[L-1], n[L]),而torch.nn.Linear内部初始化的权重的维度为(n[L],n[L-1])。我们通过一个简单的例子来说明一下:
1.假设输入层神经元个数为20,下一层(记作L1)的神经元个数为70
2.初始化L1的线性层:torch.nn.Linear(20,70)
3.L1层的weight维度为:(70,20) 偏移向量的维度为:(70,)
4.根据计算公式:y=x.AT+b,要求输入的x的维度为(n,20),n为样本个数
5.L1层的线性计算结果(可以理解为Z[1])的维度为:(n,70) 可以看出,初始化torch.nn.Linear时要使用(n[L-1], n[L]),也就是输入维度和输出维度。样本输入要采用每一行代表一个样本的方式,与吴恩达老师视频中的讲解完全相反,刚开始编程可能会有点不习惯,慢慢习惯就好。
关于weight的维度其实有点奇怪,线性层保存的weight的维度为(n[L],n[L-1]),这其实和吴恩达老师视频中的一致,但是计算的时候却进行了转置操作,这就使得x的输入与吴恩达老师视频中完全相反。